
Data Warehouse vs. Data Lake: An In-Depth Comparison
These solutions share a common goal: data storage and management. Understanding the distinctions between the two can help organizations choose the right approach, or even a combination of both, to optimize their data strategies.
What is a Data Warehouse?
Data warehouses store, organize, and analyze a large amount of historical data to support business reporting and analytics. In this data management system, data analysts consolidate data from multiple sources and model it in a structured format for end-users. This process is called data modeling.
Data modeling—the data warehouse’s blueprint—uses a predefined schema that outlines relationships and hierarchies within the data. Through a logical framework, it minimizes the risk of data inconsistencies and facilitates efficient data retrieval.
Data analysts may implement a medallion architecture with multiple levels of tables to reflect the degree of data enrichment or cleansing.
Building Reliable, Performant Data Pipelines with Delta Lake (Databricks)
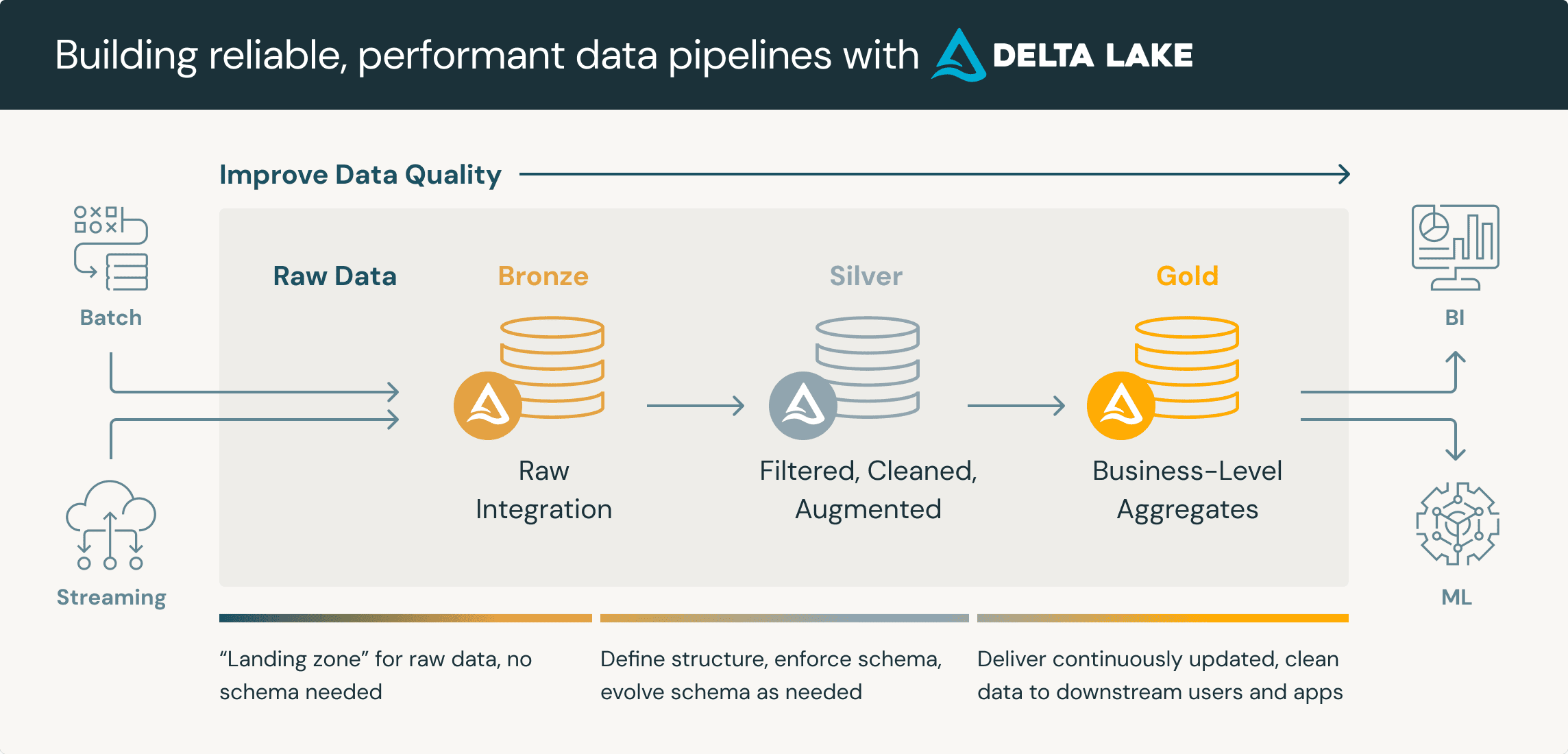
To illustrate this, consider a data warehouse designed for a retail business.
- Bronze Layer. Users ingest raw, structured data from the retailer’s POS sales transactions and inventory records. This layer captures data in its original format—thus, serving a historical archive and enabling quick access to comprehensive data lineage.
- Silver Layer. Data from the bronze layer undergoes cleansing and merging. Data analysts standardize records (e.g., customer names, date formats, product codes), eliminate duplicate entries, and consolidate information.
- Gold Layer. The layer organizes curated data into project-specific tables. E.g.: separate tables for customer behavior analysis, sales performance by category, and inventory levels
With highly organized and labeled data, retrieval and analysis based on specific attributes become straightforward. Business analysts and marketing and sales teams rely on this to analyze verified data for efficient strategic planning.
What is a Data Lake?
Data lakes are a centralized repository that stores and manages structured, semi-structured, and unstructured data. Unlike data warehouses, which require rigid schema before data ingestion, data lakes can hold data in its raw form. This reduces the need for upfront data modeling, saving time and resources.
The retailer in the previous example can gain insights not only from sales transactions and inventory levels. They can also store semi-structured data from website interaction logs and unstructured data like customer surveys, product reviews, and product images.
This schema-on-read functionality enables data power users (i.e., data scientists and engineers) to define structure only when accessing data. It’s more scalable for advanced use cases since users can quickly adapt to new data sources and formats. They can incorporate real-time data, test hypotheses, and support evolving analytics needs. However, data lakes present challenges in accessibility and usability. Non-technical, line-of-business teams need structured, reliable data that’s easy to access and interpret without extensive tech support.
A brief outline of the data lake vs. data warehouse discussion:
Data Warehouse | Data Lake | |
Data Type | Structured data | Structured, semi-structured, and unstructured data |
Schema | Schema-on-write (predefined schema before data ingestion) | Schema-on-read (structure defined when accessing data) |
Data Processing | Requires data modeling and cleansing upfront | Stores raw data, with minimal pre-processing |
Accessibility | Easily accessible for non-technical, line-of-business users | Primarily accessible to data power users (data scientists, engineers) |
Use Cases | Business reporting, analytics, and operational decision-making | Advanced analytics, machine learning, and big data processing |
Scalability | Limited scalability for unstructured data | Highly scalable, suitable for handling large volumes of diverse data |
Cost and Storage | More costly due to structured storage and processing | More cost-effective for large, diverse data sets |
Typical Users | Business analysts, sales and marketing teams | Data scientists, engineers, advanced analytics teams |
Key Limitation | Rigid structure may limit flexibility for evolving analytics | Can be complex and challenging for non-technical access |